Cross Site Scripting is defined as allowing a user to inject their client side script into your web page so that it is executed when other visitors land on that page. The impact of running such a script can range from simple defacement of the page to the theft of user sessions or the highjacking iof the user's browser using malware. So how does an attacker inject their script? The most common route is via unsanitised input that is stored and then displayed without being properly encoded or otherwise escaped. User input can come from a variety of sources - form fields, querystrings, UrlData and cookies being the most accessible (to the attacker). It is also possible to manipulate AJAX routines to inject one's own values into JSON or other values that will be posted to server-side code for processing.
ASP.NET provides a mechanism called Request Validation to act as a first line of defence against malicious input. Request Validation examines values being passed as part of any HTTP Request and will raise an exception if any of them contain what looks like HTML or script, i.e. a left angled bracket <.
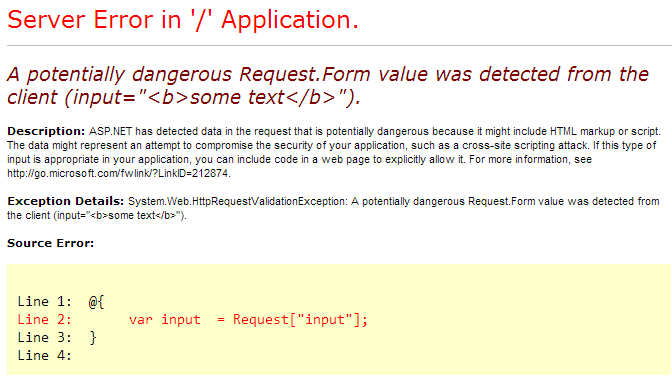
The exception is actually only raised when you attempt to programmatically access a value that looks suspicious. The exception description is "ASP.NET has detected data in the request that is potentially dangerous because it might include HTML markup or script. The data might represent an attempt to compromise the security of your application, such as a cross-site scripting attack. If this type of input is appropriate in your application, you can include code in a web page to explicitly allow it".
Sometimes it is appropriate to allow users to post HTML or even script. In such cases the built-in defence is a showstopper. However, as the description above says, there is a way round Request Validation. Each of the ASP.NET development frameworks has a different approach. When working with the Web Pages framework you will use Request.Unvalidated to reference user input that might contain HTML or script tags:
var input = Request.Unvalidated("input");
From that point, you can work with the value without exceptions getting in the way. However, if you want to display the value in the page, a second line of defence intervenes: all Razor values are automatically HTML encoded when they are rendered. That means that symbols that are part of HTML syntax, such as < or >, and & are converted to their HTML entity equivalent (<, > and &). As a result, the symbols will be rendered to the browser rather than treated as HTML. For example, if the value obtained from Request.Unvalidated("input") was '<b>some text</b>', the following will be rendered
<b>some text</b>
There seems little point in letting users post HTML unless you plan to allow it to be used as HTML. The way to get round the automatic HTML encoding is to use the Html.Raw method:
@Html.Raw(input)
This will result in the desired output:
some text
All fine so far, but Request Validation and automatic HTML encoding was added to the framework for a reason, and that was to protect against nasties. Both of those walls have been deliberately breached through the use of Request.Unvalidated and Html.Raw so now your site has a vulnerability. You need to perform some other kind of validation to protect against malicious input. Particularly, unless you are building the next JSFiddle, you are unlikely to want to allow the posting of script tags, and for most uses, you probably don't want people posting <html>, <head> <meta> or <body> tags. Nor might you want <object>, <iframe>or <embed> tags as they could provide avenues for other attacks. You could try to use something like string.Contains to find tags that you want to reject, or Regular Expressions, but matching can be extremely difficult - especially when you consider that some of the tags might have an unknown number of attributes. The open source Html Agility Pack offers a much more flexible and robust solution. And it is available from Nuget:
Request Validation with the Html Agility Pack
The Html Agility Pack converts HTML (a complete document of just a snippet) into a collection of HtmlNode objects. Once you have this collection, you can query it using LINQ to Objects. That means you can examine the input provided by users and compare it against a selection of allowed tags (whitelist) or a selection of disallowed tags (blacklist). The following example shows the use of a blacklist:
@using HtmlAgilityPack; @{ var input = Request.Unvalidated("input"); var blacklist = new List<string>{ "script", "object", "embed", "iframe", "applet", "form", "frame" }; if (IsPost) { var doc = new HtmlDocument(); doc.LoadHtml(input); var allNodes = doc.DocumentNode.Descendants(); if (allNodes.Any(n => blacklist.Contains(n.Name))) { ModelState.AddError("input", "Your submission contained banned HTML tags."); } if (Validation.IsValid()) { // } } } <!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8" /> <title></title> </head> <body> <form method="post"> @Html.TextBox("input") @Html.ValidationMessage("input")<br /> <button>Submit</button> </form> </body> </html>
First - note that the contents of the blacklist above a purely for demonstation purposes. You should not consider this to be the definitive list of HTML tags that could lead to some kind of malicious attack.
The bottom half of the code features a very simple form that consists of one textbox, one validation message helper and a submission button. At the top of the page, there is a using directive, making the HtmlAgilityPack library available to the page. A blacklist of disallowed HMTL tag names are stored in a List<string>. If the form is submitted, the content of the textbox is retrieved using the Request.Unvalidated method. It is then passed to an HtmlDocument object. Html.DocumentNode.Descendants returns a collection of HtmlNode objects, each representing an HTML tag in the document. They are compared to the blacklist, and if any matches are found, the submission is rejected and the user is informed of the reason for rejection.
Instead of rejecting input because it contained blacklisted tags, you might want to use a whiltelist to compare the submission against, and then remove any tags that do not feature in the accepted list. The following sample shows how to do that.
@using HtmlAgilityPack; @{ var allowedTags = new List<string>{ "p", "br", "div", "strong", "em", "a", "img", "ol", "ul", "li" }; var doc = new HtmlDocument(); var result = ""; if (IsPost) { var input = Request.Unvalidated("input"); doc.LoadHtml(input); RemoveNodes(doc.DocumentNode, allowedTags); var nodesWithAttributes = doc.DocumentNode.Descendants().Where(e => e.HasAttributes); foreach(var node in nodesWithAttributes.Where(n => n.Attributes.Any(a => a.Name.StartsWith("on")))) { foreach (var attribute in node.Attributes.ToList()) { if (attribute.Name.StartsWith("on")) { node.Attributes.Remove(attribute); } } } result = doc.DocumentNode.OuterHtml; } } <!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8" /> <title></title> </head> <body> <form method="post"> @Html.TextArea("input", Request.Unvalidated("input"))<br /> <button>Submit</button> </form> @Html.Raw(result) </body> </html> @functions{ static void RemoveNodes(HtmlNode node, IEnumerable<string> allowedTags) { if (node.NodeType == HtmlNodeType.Element){ if (!allowedTags.Contains(node.Name)){ node.ParentNode.RemoveChild(node); return; } } if (node.HasChildNodes) { RemoveChildren(node, allowedTags); } } static void RemoveChildren(HtmlNode parent, IEnumerable<string> allowedTags) { for (var i = parent.ChildNodes.Count - 1; i >= 0; i--) RemoveNodes(parent.ChildNodes[i], allowedTags); } }
Similar to the last sample, the code features a simple form and a collection of HTML tags. But this sample includes a couple of code routines declared using the functions keyword. The routines are RemoveNodes and RemoveChildren. The RemoveNodes method takes a node and checks to see if it is an HTML element (rather than say a Text node) and then checks to see if it's name is in the list of allowed tags. If it isn't, it removes the node. An HtmlNode can also have an unknown number of child nodes, so the RemoveChildren method recursively removes all children from the most furthest one all the way back to the offending node itself.
It is also possible to sneak an attack in via attributes - adding an onclick event to an element for example: onclick="javascript:alert('hello')". Once the input has been sanitised for disallowed elements, the remaining elements have their attributes examined for any that start with "on". These are also removed.
On balance, the safest approach is to use a whitelist, and if any nodes are found that are not in the whitelist, reject the input entirely.
JSON
Request validation only works on name/value pairs that have been sent to the server in one of the Request collections: Form, Querystring, Cookies etc. If you use AJAX to post JSON to the server, it will bypass Request Validation. Here's a code sample that illustrates the problem:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8" /> <title></title> <script type="text/javascript" src="~/Scripts/jquery-2.0.3.min.js"></script> </head> <body> <script> var text = '<script>alert("hello world")<\/script>'; var data = { "text": text }; $(function () { $('button').click(function () { $.ajax({ type: "POST", url: "/Receiver", data: JSON.stringify(data), datatype: "html", success: function (data) { $('#result').html(data); } }); }); }); </script> <button>Click</button> <div id="result"></div> </body> </html>
This sample creates a JavaScript object which has a property called "text". The value of that property is set to a snippet of (harmless, in this case) script that will cause an alert to appear in the browser if it is executed. The code also features a button and an empty div called "result". When the button is clicked, the JavaScript object is serialised to JSON and posted to a page called Receiver.cshtml. Whatever Receiver.cshtml produces as output is then set as the HTML content of the empty div. So what does Receiver.cshtml do? Well, not much:
@{ var json = ""; using(var reader = new StreamReader(Request.InputStream)){ json = reader.ReadToEnd(); } var jsonObject = Json.Decode(json); } @Html.Raw(jsonObject.text)
All it does is to unpack the JSON from the body of the request and render the text to the browser as HTML. It could just as easily take that text and store it in a database. The point however is that no exceptions are raised at any stage during the processing of the posted value. Request Validation is not invoked at all. If you ever plan to render text values posted as JSON like this and you have to use Html.Raw, you must validate the input - no matter how it was generated. It is really easy for any attacker to manipulate these values using the built in developer tools that most browsers include these days - even if the value was initially generated by your code.
