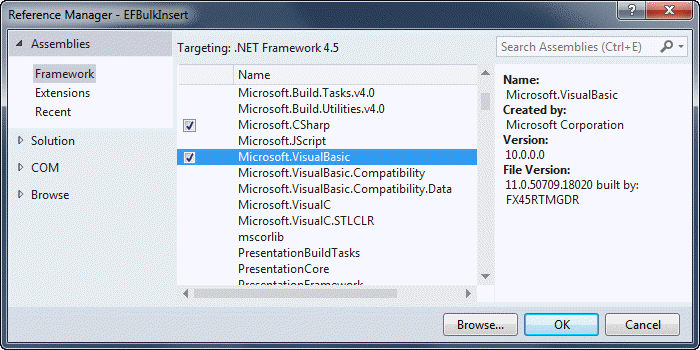
The Microsoft.VisualBasic library is a collection of namespaces containing a miscellany of components and utilities. Most of them seem to provide VB6 developers with something that they will be familiar with such as .NET implementations of the string-related Left and Right methods, but despite its name (and the fact that MSDN examples are all VB-only), the library is pure .NET code and can be used with any .NET compliant language. C# projects do not include a reference to Microsoft.VisualBasic by default, so you need to use the Add References dialog to add it yourself:
A TextFieldParser instance can be initialised from a number of sources: a stream, a physical file on disk, or a TextReader. The first two options are likely to be used more often in ASP.NET applications. This first example illustrates creating a TextFieldParser from an uploaded file in an MVC application:
[HttpPost] public ActionResult Index(HttpPostedFileBase file) { if (file != null) { if (file.ContentLength > 0) { using (var parser = new TextFieldParser(file.InputStream)) { // ... } } } return View(); }
The TextFieldParser is instantiated within a using block because it implements IDisposable, and the using block ensures that the object will be displosed of safely and correctly. The next example sees a file path passed to the TextFieldParser constructor:
var file = @"C:\test.csv"; using (var parser = new TextFieldParser(file)) { //.. }
Finally, here's an example of the constructor that accepts a concrete implementation of the TextReader:
var csv = @"1,Mike,Brind,www.mikesdotnetting.com"; using (var parser = new TextFieldParser(new StringReader(csv))) { // ... }
Configuration
Configuration options are set through properties and methods. The key options are featured below:
| Option | Description | Default |
|---|---|---|
Delimiters (property) |
Specifies the field delimiters used in the text file. | null |
SetDelimiters (method) |
Alterntative way to specify the field delimiters used in the file | |
TextFieldType (property) |
Specify whether the file is Delimited or FixedWidth |
TextFieldType.Delimited |
HasFieldsEnclosedInQuotes (property) |
Boolean indicating whether text fields are enclosed in quotes |
true |
FieldWidths (property) |
An array of ints specifying the widths of individual fields in a fixed width file |
null |
SetFieldWidths (method) |
An alternative way to specify the widths of individual fields in a fixed width file | |
CommentTokens (property) |
An array specifying the tokens used to indicate comments in the file | null |
TrimWhiteSpace (property) |
Boolean indicating whether leading and trailing white space should be removed from fields |
true |
Having instantiated and configured a TextFieldParser, you will want to start accessing the data in the text file. The parser has a ReadFields method that gobbles up content a line at a time. It returns an array of strings. It also has an EndOfData property which indicates whether there are any more lines of data to be read. The following code shows how to use this property and method in combination to read each line of data in a simple example:
var data = @"1,Potato,Vegetable 2,Strawberry,Fruit 3,Carrot,Vegetable 4,Milk,Dairy, 5,Apple,Fruit 6,Bread,Cereal"; using (var parser = new TextFieldParser(new StringReader(data))) { parser.Delimiters = new[] { "," }; while (!parser.EndOfData) { var row = parser.ReadFields(); var foodType = row[2]; } }
The sample above doesn't have a header. The following sample features the same data with a header row, and illustrates how to copy the whole thing into a DataTable:
var data = @"Id,Food,FoodType 1,Potato,Vegetable 2,Strawberry,Fruit 3,Carrot,Vegetable 4,Milk,Dairy, 5,Apple,Fruit 6,Bread,Cereal"; using (var parser = new TextFieldParser(new StringReader(data))) { var headerRow = true; var dt = new DataTable(); parser.Delimiters = new[] { "," }; while (!parser.EndOfData) { var currentRow = parser.ReadFields(); if (headerRow) { foreach (var field in currentRow) { dt.Columns.Add(field, typeof(object)); } headerRow = false; } else { dt.Rows.Add(currentRow); } } }
The final example shows how to apply the CommentTokens property to be able to read a standard IIS log file into a DataTable where comment lines are prefixed with a hash (#) symbol:
var file = @"C:\Logs\W3SVC6\ex140210.log"; var commentTokens = new[] { "#" }; var headerRow = File.ReadAllLines(file).First(l => l.StartsWith("#Fields:")); using (var parser = new TextFieldParser(file)) { var dt = new DataTable(); var columns = headerRow.Replace("#Fields: ", string.Empty).Split(new[] { ' ' }, StringSplitOptions.RemoveEmptyEntries); foreach (var column in columns) { dt.Columns.Add(column, typeof(object)); } parser.SetDelimiters(" "); parser.CommentTokens = commentTokens; while (!parser.EndOfData) { { dt.Rows.Add(parser.ReadFields()); } } }
In this case, because the parser is configured to ignore lines beginning with the specified comment token, a bit of additional code is used to extract the field headers for the DataTable column names.
Summary
Next time you need to parse a text file in a .NET application, rather than reaching for string manipulation functions, you could consider using the TextFieldParser in the Microsoft.VisualBasic library.
