The full series of articles consists of
- Content - Describing your content to search engines
- URLs - how to optimise your URLs for search
- Indexing - mechanisms that help to ensure the correct parts of your site are found by search engines
Uniform Resource Locators
The URL (or Uniform Resource Locator) for any given page specifies the address where it is located and the mechanism (protocol) by which is can be retrieved. For web pages, the protocol will be http or https in the vast majority of cases. This is typically followed by the domain and then a unique identifier of some description. Ideally, the URL should describe the content and include key words that are also present in the page title, description and content.
In a previous version of my site, the URL for this article would have been
http://www.mikesdotnetting.com/article.aspx?id=290
This doesn't provide any clue to humans as to the content of the resource and is therefore not descriptive at all. It provides no help either to search engines in understanding where the page fits in the Internet, and more reliance is placed on the other three sources of information for a search engine: title, description and content. These days, the URLs are a lot better from an SEO point of view:
http://www.mikesdotnetting.com/article/290/seo-for-asp-net-web-sites-urls
It should be obvious to anyone reading just the URL what the content of the page is likely to cover.
SEO and User Friendly URLs
The URL scheme for the previous version of my site was driven by the fact that older Web Forms versions relied on URLs matching the name and path of physical files. Any dynamic values, such as the identifier for which article should be displayed, is passed as query string parameters. It would have been possible to pass the title of the article as a query string parameter. However, the advice from search engines is to avoid query strings if at all possible, and where it is not possible to avoid them, to keep them very few in number and short.
When Dynamic Data was introduced in ASP.NET 3.5 (SP1), a new routing system was also introduced that allowed the developer to map arbitrary URL patterns to physical files. This was adopted for use in the MVC framework that came out at about the same time - although in the case of MVC, URLs are mapped to action methods on controllers by convention.
Friendly URLs And Routing
Web Forms still works on the basis of mapping URLs to physical files, but it also includes a new system for generating and working with friendly URLs called - ahem - "Friendly URLs". It is based on the same paradigm as the default routing system that comes as part of the Razor Web Pages framework. The default setup will match a URL to a physical file without the file extension being included in the URL, and it also caters for arbitrary pieces of data to be passed in the URL as additional segments. In other words, it is a convention-based system that relies on some or all of the URL matching the virtual file path for a web form (.aspx file). Friendly URLs is available as a Nuget package (Microsoft.AspNet.FriendlyUrls) and is pre-installed and enabled as part of the standard Web Forms project template.
Given an example URL of http://localhost:1234/article/101/seo-for-asp-net-web-sites-urls, the following code shows how to extract values from segments using the Friendly URLs package in Article.aspx, and then assign them to Literal controls called ID and Headline, and how to generate a hyperlink using a HyperLink control too:
protected void Page_Load(object sender, EventArgs e) { var segments = Request.GetFriendlyUrlSegments(); if (segments.Any()) { ID.Text = "ID: " + segments[0]; Headline.Text = "Headline: " + segments[1]; Link.Text = Link.NavigateUrl = FriendlyUrl.Href("~/article", segments[0], segments[1]); } }
The GetFriendlyUrlSegments method is an extension method located in Microsoft.AspNet.FriendlyUrls, so you also need a using directive at the top of the file to bring that namespace in to scope. The method will return aList<string>that contains the values in any segments after the file name. The FriendlyUrl.Href helper method generates URLs from the virtual path and segment values provided. This is assigned to both the Text and NavigateUrl properties of the Hyperlink control.

Friendly URLs is a very easy system to use for Web Forms sites where relatively straightforward URL schemes are in use and a match between the URL and the filename without the extension is acceptable. For anything else, routing is usually the recommended option.
Routing
Routing works slightly differently depending on whether you are developing a Web Forms site or an MVC site. Fundamentally, they both have the same basis - you map URLs to resources when the application starts up, and incoming requests are checked against the map (or route table) to see where they should be directed. However, in a Web Forms site, all incoming URLS have to mapped to physical files. Since there is no presumed association between the content of the URL and the file system on the web server, each URL has to be configured. It is possible to use both Friendly URLs and routing in the same site, so this can make the job of configuration much easier where most URLs actually do correspond to the file name without the extension. The following section of code shows the default RouteConfig class found in the App_Start folder in the Web Forms template:
public static class RouteConfig { public static void RegisterRoutes(RouteCollection routes) { var settings = new FriendlyUrlSettings(); settings.AutoRedirectMode = RedirectMode.Permanent; routes.EnableFriendlyUrls(settings); routes.MapPageRoute("", "test/{id}", "~/mytest.aspx"); } }
The first three lines of code in the RegisterRoutes method enable Friendly URLs, and specify that by default, requests for e.g. http://domain.com/contact.aspx result in a 301 Moved Permanently status code and a location of http://domain.com/contact (without the extension).
The final line of code using routing to map requests for http://domain.com/test/xxx to mytest.aspx. The xxx can be any value at all, but must be present for the route to work. You can make that part of the URL optional, or you can constrain the value to a particular pattern using regular expressions. You can read more about how to do that in MSDN's overview of ASP.NET routing.
Friendly URLs will always win in the event of a routing entry matching a virtual file path for a .aspx file on the server. For example, if someone was to add a file called Test.aspx to the root folder of the site in the above example, Friendly URLs will take care of the direct match between the URL and the file system, and the routing entry will never be invoked.
In an MVC site, routing is the only system for mapping URLs to resources, because there are no files to map to. For most sites, you don't ever need to go beyond the single route that's defined by default:
public static void RegisterRoutes(RouteCollection routes) { routes.IgnoreRoute("{resource}.axd/{*pathInfo}"); routes.MapRoute( name: "Default", url: "{controller}/{action}/{id}", defaults: new { controller = "Home", action = "Index", id = UrlParameter.Optional } ); }
This route definition specifies that the first URL segment contains the controller name, the second contains the Action method's name an the third segment is optional, but if it is populated, it can be matched to a parameter named id. The default value for the controller segment is Home, and the default for the action segment is Index.
If you want to generate URLs for use in anchor href or image src attributes or similar in MVC 5 or earlier, you have a number of helper methods to choose from: ActionLink, RouteLink and the UrlHelper's Action and Route methods. In MVC you also have the option to use the new Anchor TagHelper., where the action and contoller are specified as special asp- attributes on HTML elements:
<a asp-action="Index" asp-controller="Home">Back Home</a>
Slugs
Slug is a term that's often used to describe the human-readable portion of the URL. On my site, I use the article title as a slug, and therefore choose my article titles carefully to ensure that they contain relevant keywords. I also reuse the article title as the page title and the content of an h1 heading so that the keywords are found consistently throughout the page. The ASP.NET forums and Stackoverflow use the wording of the posted question as a slug. However, they use different word separators: the ASP.NET forums use a plus ( + ) sign between words, whereas Stackoverflow uses hyphens ( - ). The people at Google recommend the use of hyphens.
A question that comes up pretty frequently is how to generate a slug that can safely take account of punctuation and other reserved characters. The guys at Stackoverflow have posted the slug generation method they use. I use a variation of their algorithm that has the 80 character limit that they employ removed. Many SEO experts recommend that you should keep URLs to a maximum of 75-80 characters as that is the maximum number of characters that an entry on SERPs will show. However, Google in particular tends to truncate URLs for display to highlight the relevant key words, replacing non-keyword segments with ellipses. There is no advice from Google on setting a maximum length for a URL, so it seems that they are not really bothered.
Canonical URLs
There should only be one valid URL per resource. This is known as the canonical URL. The danger with having multiple URLs pointing to the same resource is that the ranking for any given page will be diluted across the various URLs. The following URLs may all look the same:
http://www.mikesdotnetting.com/article/290/seo-for-asp-net-web-sites-urls http://mikesdotnetting.com/article/290/seo-for-asp-net-web-sites-urls http://www.mikesdotnetting.com/article/290/Seo-For-Asp-Net-Web-Sites-URLs
Indeed they will all result in the same content being extracted from the database and the same source code in the resulting page (at least on my site...). But they are all different from an SEO point of view - even the one with different casing. For that reason, you must be consistent in the URLs you use in your navigation and other in-site links.
Despite your best efforts to manage this in your own code, there are other ways in which your page's SEO can become fragmented as a result of multiple URLs pointing to the same resource. You can't avoid the possibility of other people creating variations of your URLs when linking to you from their own site, forums or social media etc. For this reason, you are advised to use an HTML link element in every page to inform search engines what the canonical URL for this particular page is:
<link rel="canonical" href="http://www.mikesdotnetting.com/article/290/seo-for-asp-net-web-sites-urls" />
Redirecting non-www to www URLS
Most domains are set up with an @ record that points their domain in its purest form (e.g. domain.com) to their web server's IP address and a CNAME record that points www.domain.com to the @ record. Then both domain.com and www.domain.com are added as bindings for the site in IIS. This is useful for those visitors that type a web address without the www prefix. It will ensure that the request is routed to the correct server. As I have already mentioned, this results in two valid URLs for the same content, and while that issue can be taken care of with the use of rel="canonical", you can also use an HTTP redirect if your IIS server has URL Rewrite installed. You don't even need access to the web server to set up a rewrite rule. You can do it in your site's web.config.
<system.webServer> <rewrite> <rules> <rule name="Redirect non-www traffic to www" stopProcessing="true"> <match url=".*" ignoreCase="true" /> <conditions> <add input="{HTTP_HOST}" pattern="^mikesdotnetting.com$" /> </conditions> <action type="Redirect" url="http://www.mikesdotnetting.com/{R:0}" redirectType="Permanent" /> </rule> </rules> </rewrite> </system.webServer>
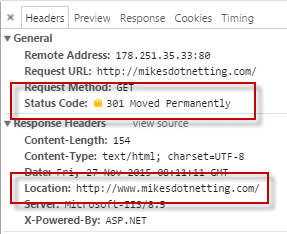
This rewrite rule covers requests for any URL that matches the pattern .*, which basically covers everything. It will examine the host part of the URL, and if doesn't start with "www." the server responds with a 301 - Permanently Moved status code and a new location with the preceding www.
Summary
This article covered the role that URLs play in Search Engine Optimisation. It looked at the importance of having user- and seo-friendly URLs and how to generate and work with them in both ASP.NET Web Forms and MVC applications. Finally, canonical URLs were explained, and strategies were described for managing them.
In the next article, I will look at how you can manage the content that search engines index on your site.
